从规则引擎开发的角度切入编译器原理 | 青训营笔记
这是我参与「第五届青训营」伴学笔记创作活动的第 6 天
前言
本文试图从规则引擎开发的角度切入编译器原理相关内容,介绍编译原理的基本概念。
认识规则引擎
什么是规则引擎
业务规则引擎是在运行时生产环境中执行一个或多个业务规则的软件系统。这些规则可能来自法律法规(“员工可以因任何原因或无理由被解雇,但不能出于非法原因”)、公司政策(“所有一次花费超过 100 美元的客户将获得 10% 的折扣”)或其他来源。业务规则系统使这些公司策略和其他操作决策能够独立于应用程序代码进行定义、测试、执行和维护。 —— Wikipedia
思考如下例子:某商城开设一个活动,用户购买相应产品获得可以商城积分(对应某种业务逻辑),听起来用代码实现会很简单。但是,如果积分获取规则不断更改(对应业务逻辑的更改),那么程序员就需要不断地修改代码以实现业务逻辑,这无疑增加了无意义的工作。
规则引擎则是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策。这样,业务人员便可以通过规则引擎直接修改规则决策,而避免通过开发人员修改,增加工作效率,同时解耦合了工作。
规则引擎的组成
规则引擎由三部分组成:
- 数据输入。接受使用预定义的语义编写的规则作为策略集,比如
price > 500,接受业务的数据作为执行过程中的的参数,比如价格、标签等; - 规则理解。能够按照预先定义的词法、语法、优先级、运算符等正确理解业务规则所表达的语义;
- 规则执行。根据执行时输入的参数对策略集中的规则进行正确的解释和执行。同时对规则执行过程中的数据类型进行见擦汗,确保执行结果正确。
规则引擎的应用
- 风控对抗
- 活动策略运营
- 数据分析和清洗
- ……
编译原理基本概念
词法分析(Lexical Analysis)
词法分析就是把源代码字符串转换为词法单元(Token)的过程。
例如,price > 500 && (isNewUser || userLevel > 5) 这段表达式可被分割为 price, >, 500, &&, (, isNewUser, ||, userLevel, >, 5, ) 几部分(Token)。
我们可以通过有限自动机(Finite-State Automaton)来对 Token 进行识别。有限自动机就是一个状态机,他的状态数量是有限的,该状态机在任何一个状态,基于输入的字符,都能做一个确定的状态转换。
词法分析结束后,我们通过语法分析来识别表达式。
语法分析(Syntax Analysis)
语法分析就是在词法分析的基础上,识别表达式的语法结构的过程。
例如,上文中 price, >, 500, &&, (, isNewUser, ||, userLevel, >, 5, ) 可被识别为如下几部分:
price > 500,其中>为操作符,price为左操作数,500为 右操作数;isNewUser || userLevel > 5,其中||为操作符,isNewUser为左操作数,userLevel > 5为右操作数;userLevel > 5,其中>为操作符,userLevel为左操作数,5为右操作数;price > 500 && ( isNewUser || userLevel > 5 ),其中&&为操作符,price > 500为左操作数,( isNewUser || userLevel > 5 )为右操作数。
通过语法分析,我们可为表达式构造抽象语法树。
抽象语法树(Abstract Syntax Tree)
在计算机科学中,抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。 —— Wikipedia
一支抽象语法树看起来大致是这个样子:
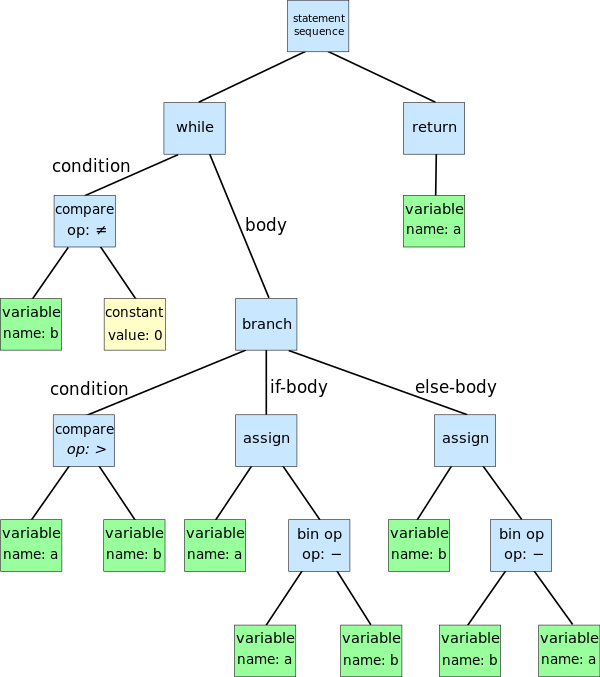
以上抽象语法树表示了以下伪代码,使用辗转相除法求最大公约数:
while b ≠ 0:
if a > b:
a := a - b
else:
b := b - a
return a
巴科斯范式(BNF)
对于上下文无关语法(Context-Free Grammar,无须考虑上下文就可以判断正确性的语句),可使用巴科斯范式来表达:
exp : add;
add : add '+' mul | mul; // 加法表达式,可匹配 a + b + c 或 a + b * c
mul : mul '*' pri | pri; // 乘法表达式,可匹配 a * b * c
pri : string | bool | number | identifer; // 基础表达式,可匹配 weight 或 20 或 "abcde"
以上每一行被称为产生式。可代指一种可以由另外已知类型的表达式或者符号推导产生的表达式。
本例中,pri(代指基础表达式)可由常量(string, bool, number)或标识符(identifer)组成;mul(代指乘法表达式)可由 pri 或 mul * pri 组成,以此类推。
递归下降算法(Recursive Descent Parsing)
我们可以使用递归下降算法构造语法树,其通过递归的形式不断地对 Token 进行向下语法展开来构造抽象语法树。
类型检查
- 类型综合。根据子表示的类型构造出父表达式的类型。例如,表达式 A+B 的类型是根据 A 和 B 的类型定义的。
- 编译时检查 & 运行时检查。
引用
该文章部分内容来自于以下课程或网页:
- 「【实践课】规则引擎设计与实现」第五届字节跳动青训营 - 后端专场
- Business rules engine - Wikipedia
- 抽象语法树 - Wikipedia
分发
This work is licensed under CC BY-SA 4.0![]()
![]()
![]()